Is Your Process Data Spread Smooth or Chunky?
Just the Facts
DOFPro Team

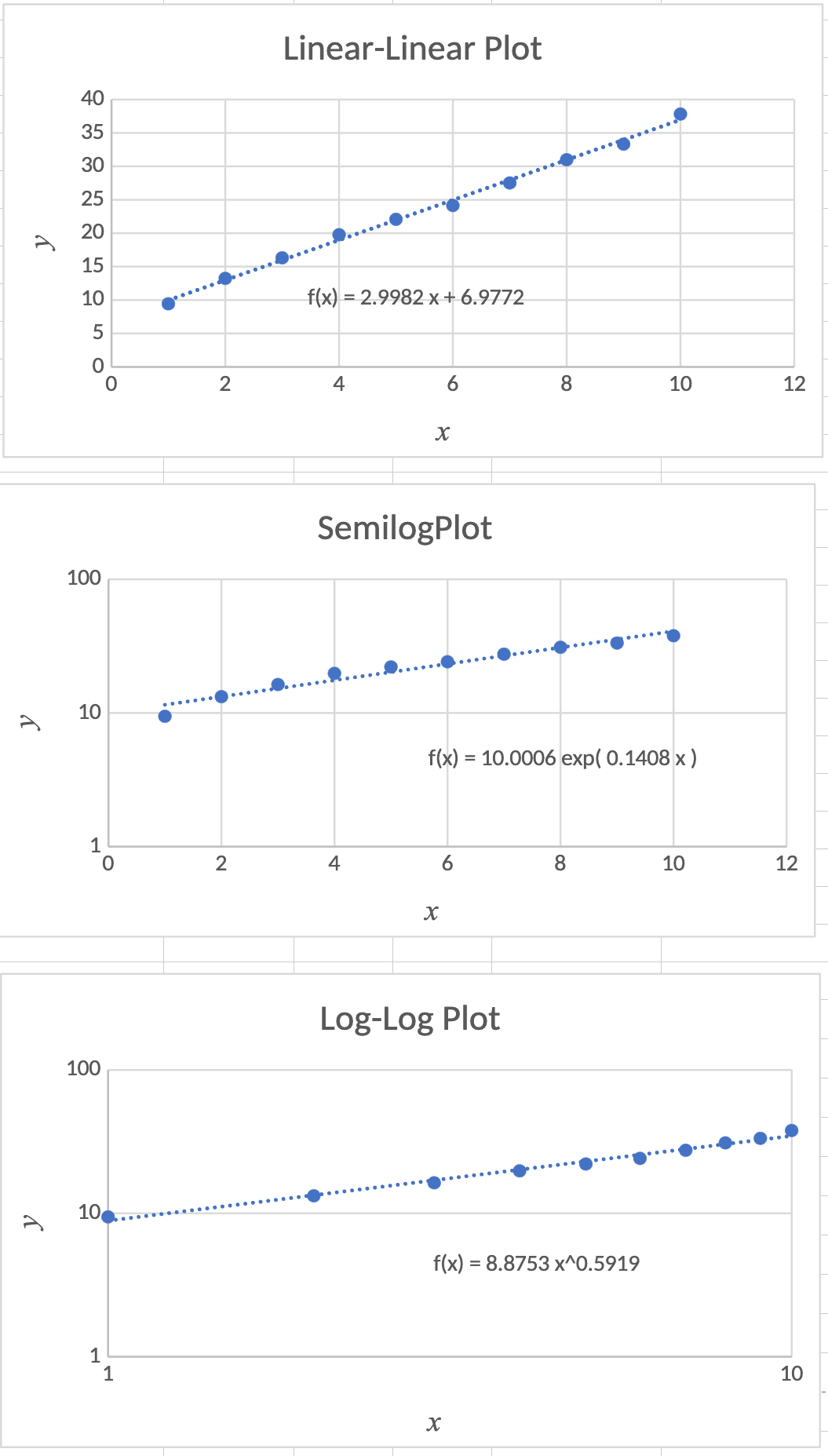
Sample Linear Data
| \(x\) | \(y\) |
|---|---|
| 1 | 9.44 |
| 2 | 13.24 |
| 3 | 16.32 |
| 4 | 19.77 |
| 5 | 22.08 |
| 6 | 24.15 |
| 7 | 27.52 |
| 8 | 30.99 |
| 9 | 33.33 |
| 10 | 37.83 |
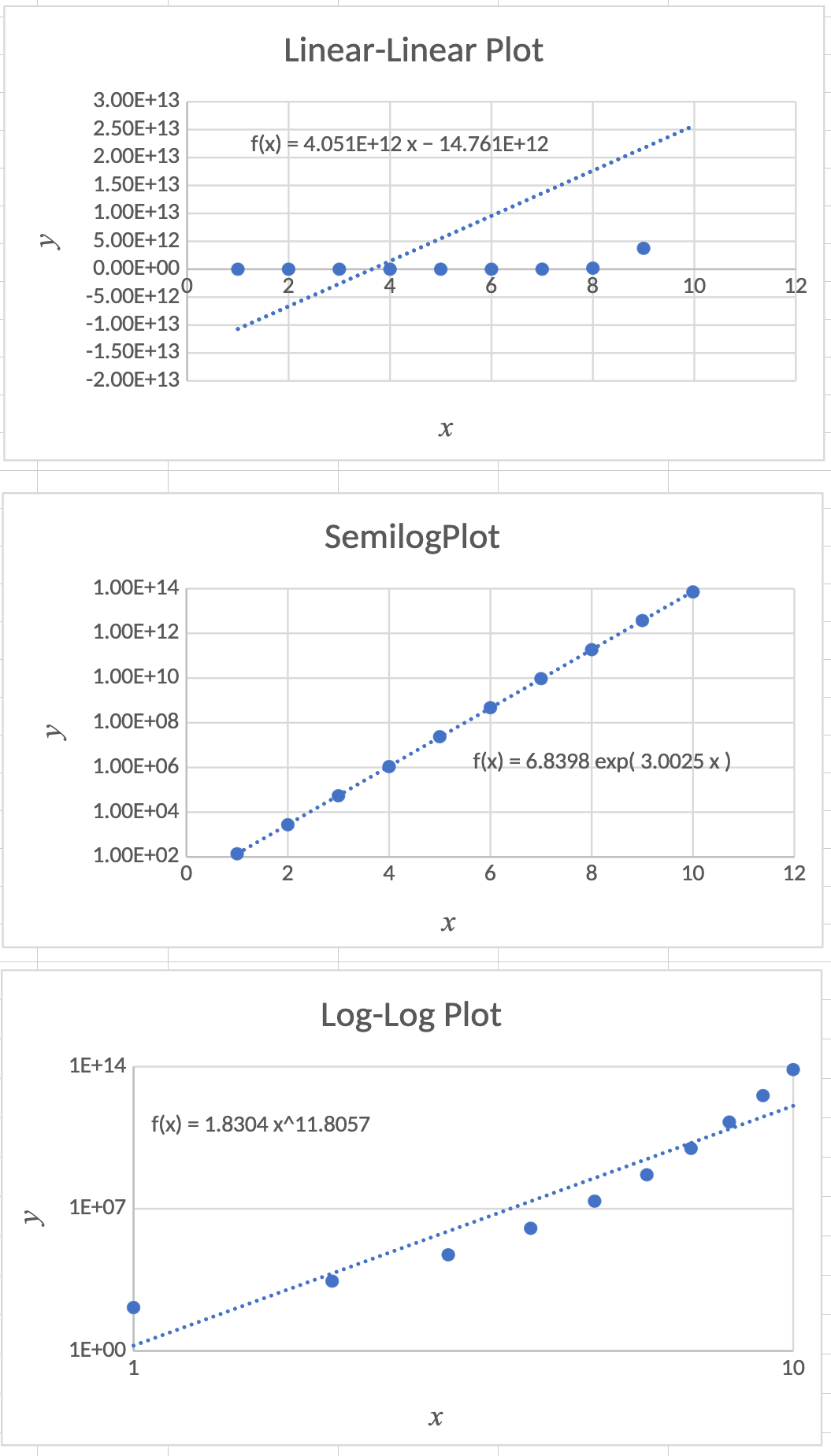
Sample Semilog Data
| \(x\) | \(y\) |
|---|---|
| 1 | 1.38E+02 |
| 2 | 2.74E+03 |
| 3 | 5.42E+04 |
| 4 | 1.09E+06 |
| 5 | 2.38E+07 |
| 6 | 4.71E+08 |
| 7 | 9.39E+09 |
| 8 | 1.86E+11 |
| 9 | 3.74E+12 |
| 10 | 7.12E+13 |
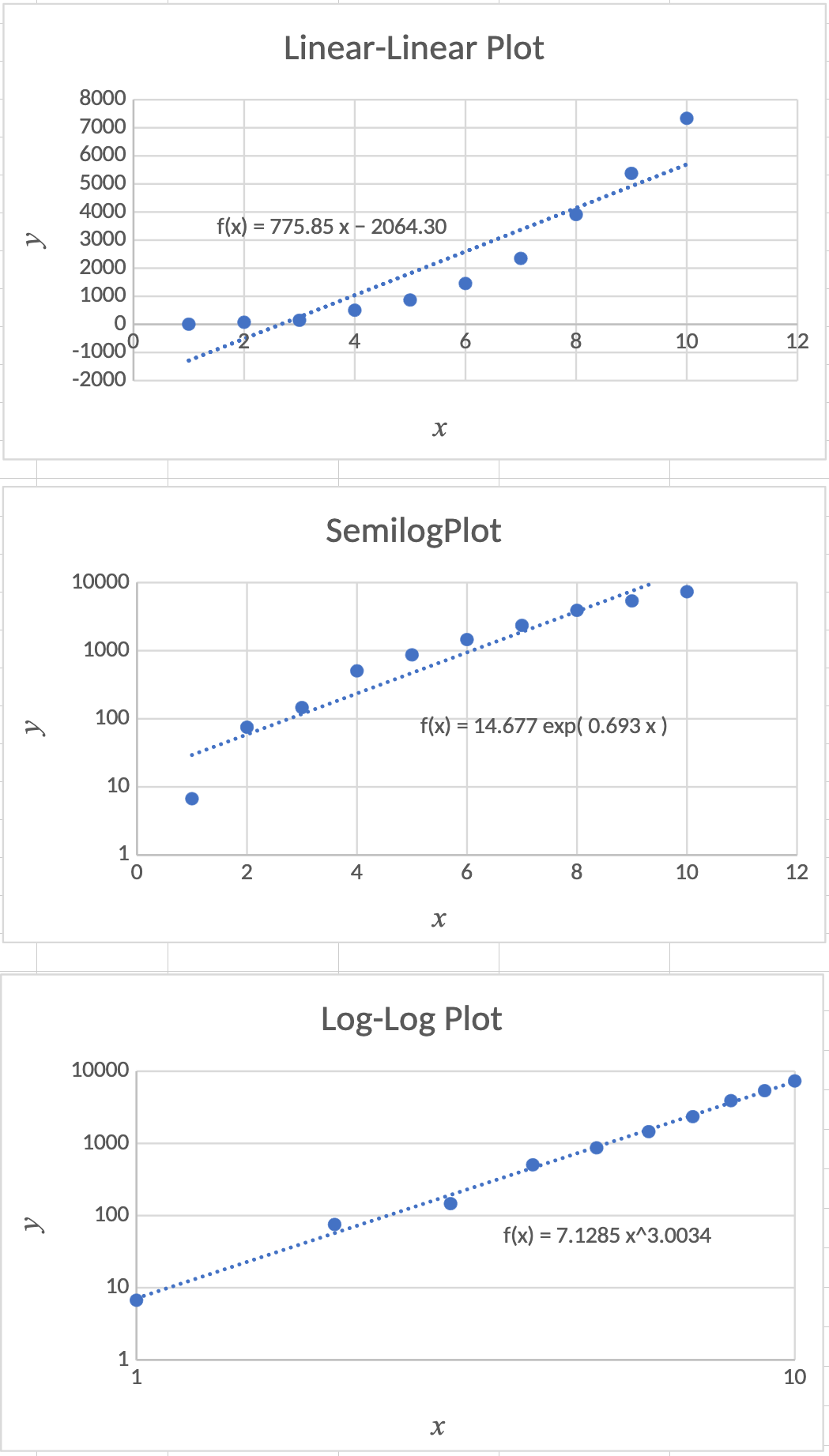
Sample Log-Log Data
| \(x\) | \(y\) |
|---|---|
| 1 | 6.706 |
| 2 | 75.22 |
| 3 | 146.2 |
| 4 | 504.7 |
| 5 | 868.2 |
| 6 | 1456 |
| 7 | 2349 |
| 8 | 3910 |
| 9 | 5377 |
| 10 | 7336 |
Thanks for watching!
The Full Story companion video is in the link in the upper left. The next video in the series is in the upper right. To learn more about Chemical and Thermal Processes, visit the website linked in the description to find previous and following videos in this series.
The DOFPro Team